Duplicate content is one of the most misunderstood topics in SEO.
Many website owners fear it, thinking Google will penalize their site for having similar content on multiple pages.
The truth is different.
Google has clearly stated there is no penalty for duplicate content unless it’s used to manipulate search results or deceive users.
However, that doesn’t mean duplicate content is harmless.
Duplicate pages can confuse search engines about which version to index, dilute backlinks, and waste crawl budget.
As a result, your important pages may not get the visibility they deserve.
A 2024 Semrush analysis found that 29% of websites contain duplicate content issues, often caused by technical settings, URL parameters, or content syndication.
These issues may not trigger penalties, but they do weaken SEO performance over time.
In this article, you’ll learn:
- What duplicate content really is and how it impacts SEO
- What Google officially says about it
- How to handle duplicates with canonical tags and other methods
- How to detect and monitor duplicate content
- How duplicate content affects backlinks and authority
- And finally, how this issue plays a new role in the AI-driven SEO era
What is Duplicate Content and Why It Matters
Duplicate content means having the same or very similar text on more than one URL.
It can happen within your website or across multiple websites.
Search engines face a challenge when they find duplicates. They need to decide which version to index and show to users.
This decision can split ranking signals, dilute backlinks, and reduce your site’s visibility.
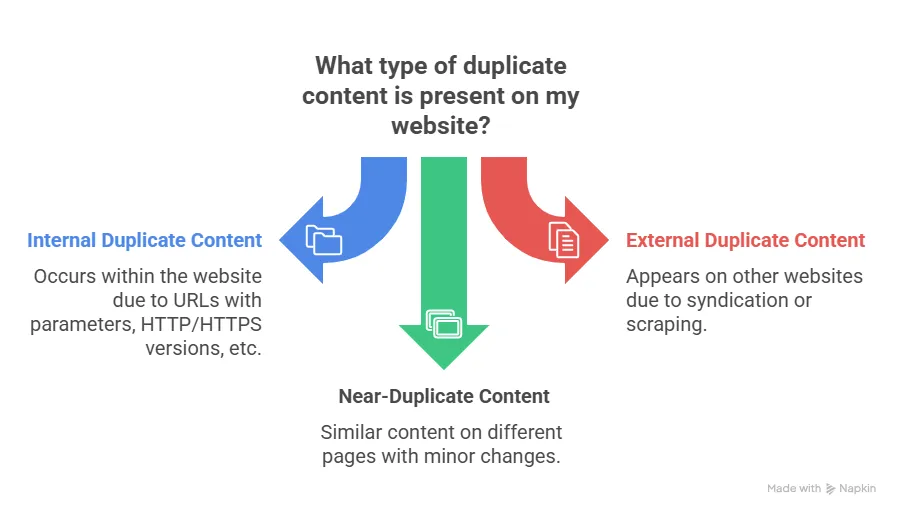
Types of Duplicate Content
- Internal Duplicate Content
This happens when the same content appears on multiple pages within your own website.
For example:- URLs with tracking parameters
- HTTP and HTTPS versions
- “www” and non-“www” versions
- Print-friendly pages or tag archives
https://example.com/pageandhttps://example.com/page?ref=123
Both show the same content but are treated as different URLs. - External Duplicate Content
This occurs when your content appears on other websites.
It might be due to syndication, scraping, or content reuse.
If Google finds multiple versions of the same text across domains, it will index only one.
Sometimes, it’s not your version. - Near-Duplicate or Similar Content
This happens when several pages cover the same topic with minor changes.
For example, multiple product pages with identical descriptions or several “location” pages with only city names changed. These pages can still confuse search engines and divide ranking power.
Why Duplicate Content Matters
Duplicate content doesn’t always cause a penalty, but it causes problems.
- Confuses Search Engines: Google struggles to choose which page to index or rank.
- Dilutes Ranking Signals: Backlinks and engagement split between versions.
- Wastes Crawl Budget: Search engines spend time crawling duplicates instead of new content.
- Hurts Analytics Accuracy: Traffic and ranking data spread across multiple URLs.
A 2024 SiteGuru report found that over 32% of crawl budgets are wasted on duplicate URLs for medium-sized websites.
That’s valuable crawl time lost — time that could have been used to index fresh, important pages.
Duplicate content is not about penalties. It’s about missed opportunities.
Managing it well ensures your SEO signals stay strong, your links consolidate, and your content performs to its full potential.
Google’s Official Stance – No Penalty but Risk of Filtering
Many SEO professionals and business owners still believe Google penalizes websites for duplicate content.
That belief is outdated. Google has clearly stated there is no direct penalty for duplicate content.
The confusion started years ago when people mixed up “penalty” and “filtering.”
Google clarified this long ago on its official blog and documentation.
Google’s Official Statement
According to Google:
“Duplicate content on a site is not grounds for action unless it appears that the intent of the duplicate content is to be deceptive and manipulate search results.”
(Source: Google Search Central Blog)
That means Google does not punish normal duplication caused by:
- Product descriptions reused across pages
- URL parameters
- Mobile or printer versions of pages
- Syndicated content with proper attribution
However, Google may still filter out duplicate pages.
When multiple versions of the same content exist, it selects one canonical version to show in search results.
What Actually Happens
Instead of penalizing duplicates, Google:
- Clusters all similar pages together.
- Chooses one version (the most authoritative or clearly canonical).
- Ignores or filters the rest from search results.
This process avoids cluttering search results with repeated pages.
But for website owners, this means some of their pages won’t appear in search — even if those pages had backlinks or conversions.
When Duplicate Content Becomes a Real Problem
Duplicate content only becomes a serious issue when it’s intentionally manipulative.
For example:
- Copying articles from other sites to gain rankings.
- Creating doorway pages with small variations.
- Republishing content to target the same keyword with multiple URLs.
In those cases, Google may apply a manual action for spam or low-quality content.
But for normal sites, the issue is not a penalty — it’s a loss of visibility and link equity.
In Simple Words
You won’t get penalized for honest duplication.
But you might lose traffic if Google picks the “wrong” version to show.
That’s why canonical tags, redirects, and consistent URL management are essential to guide Google toward the preferred version.
Canonical Tags & Other Technical Methods to Handle Duplicate Content
When you have multiple pages with the same or similar content, search engines need a clear signal to know which version is the main one.
That’s where canonical tags and other technical methods come in.
1. What is a Canonical Tag?
A canonical tag tells search engines which version of a page should be treated as the “main” or “preferred” version.
It looks like this in your page’s HTML:
<link rel="canonical" href="https://example.com/preferred-page/" />
This tag tells Google that the preferred page is at that specific URL.
Even if similar versions exist, Google should consolidate ranking signals to that page.
2. Why Canonical Tags Matter
- They prevent duplicate content issues by merging ranking signals.
- They protect link equity, ensuring backlinks to duplicates still benefit the canonical version.
- They help with content syndication, telling Google which source is the original.
- They improve crawl efficiency, reducing wasted resources on duplicate URLs.
When used correctly, canonical tags guide search engines without needing to remove or block duplicates.
3. How to Implement Canonical Tags
Here are some best practices:
- Use Self-Referencing Canonical Tags
Every important page should have a canonical tag pointing to itself.
Example:<link rel="canonical" href="https://example.com/page/" />This confirms the page is the preferred version. - Use Absolute URLs, Not Relative Ones
Always use the full URL includinghttps://and domain name. - One Canonical per Page
Multiple canonical tags on the same page confuse crawlers.
Keep only one. - Avoid Canonical Loops
Page A pointing to Page B, and Page B pointing back to Page A — this creates a loop and weakens signals. - Use Cross-Domain Canonical Tags for Syndicated Content
If your article appears on another website, add a canonical tag on the partner site pointing back to your original URL.
This protects your authority and prevents duplication issues.
4. Other Technical Methods to Handle Duplicate Content
Canonical tags are not the only solution. Depending on the situation, you can use other technical options too.
- 301 Redirects:
Use permanent redirects when you merge duplicate pages or move content.
This passes almost all link equity to the target page. - Noindex Meta Tag:
Use<meta name="robots" content="noindex">when you want to keep a page accessible but not indexed.
Example: print versions, login pages, or duplicate archives. - Parameter Handling in Search Console:
If your site uses URL parameters (like filters or session IDs), define how Google should treat them inside Google Search Console → Crawl → URL Parameters. - Consistent Internal Linking:
Always link to your canonical URLs within your site.
Inconsistent linking can confuse crawlers and split authority.
5. Common Mistakes to Avoid
- Setting canonical tags to redirected pages.
- Using canonicals on pages blocked by robots.txt.
- Forgetting to update canonicals after domain migration.
- Having canonicals that point to non-existent pages.
In Short
Canonical tags tell Google which version of your content matters most.
When implemented correctly, they keep your rankings, backlinks, and crawl budget focused on the right URLs.
They are one of the most powerful yet underused tools in technical SEO.
Detection and Monitoring of Duplicate Content
Finding duplicate content is the first step toward fixing it.
Many websites have duplicate issues without realizing it.
They can come from URL parameters, session IDs, print versions, or simple copy-paste content.
The good news is, there are reliable tools and methods to detect and monitor duplicates easily.
1. Use SEO Audit Tools
Several SEO tools can scan your entire site and highlight duplicate pages, titles, or meta descriptions.
Popular ones include:
- Screaming Frog (Desktop crawler for technical audits)
- Ahrefs Site Audit
- SEMrush Site Audit
- SiteGuru
- Siteliner (Free for smaller sites)
These tools show duplicate URLs, percentage of similarity, and which pages share the same content.
Tip: Run a site audit at least once every quarter to keep your index clean.
2. Check Google Search Console
Google Search Console (GSC) is your best free resource.
In the “Pages” section, look for these issues:
- “Duplicate, submitted URL not selected as canonical”
- “Duplicate, Google chose different canonical than user”
These alerts tell you that Google has detected duplicate or near-duplicate content and has chosen a different version to show.
This doesn’t mean you’re penalized, but it’s a sign that your canonical signals need review.
3. Manual Spot Checks
Sometimes, tools miss subtle duplicates.
You can run manual checks using these methods:
- Use the “site:” operator in Google with parts of your content in quotes.
Example:site:example.com "exact sentence from your page"
This will show if multiple URLs contain the same text. - Compare titles and meta descriptions for repetition.
- Review tag, category, or archive pages in CMS platforms like WordPress — these often produce hidden duplicates.
4. Detect External or Cross-Domain Duplicates
If your content appears on other sites (like guest posts or syndications), use these tools:
- Copyscape – Checks web-wide duplication.
- Plagium – Good for short content and paragraphs.
- Ahrefs Backlink Tool – Helps identify sites linking to or copying your content.
If other websites republish your content, ensure they include a canonical tag pointing to your original page or a rel=”nofollow” link for credit.
5. Identify Common Technical Sources of Duplicates
Many duplicate content issues are not content mistakes but technical errors.
Watch out for these:
- URL parameters (
?ref=,?sort=,?id=) - Session IDs
- HTTP and HTTPS both accessible
- “www” and non-“www” URLs both active
- Printer-friendly pages
- Pagination issues (
page/1/,page/2/) - Tag and category archives in WordPress
Fixing these improves crawl efficiency and avoids index dilution.
6. Monitor Indexing and Canonical Signals
After applying canonical tags or redirects, monitor your results.
Use:
- Google Search Console → Inspect URL to see which version is indexed.
- Site audits to confirm canonical consistency.
- Analytics to track which URLs receive organic visits.
It can take a few weeks for Google to re-crawl and apply new canonical preferences.
In Short
Duplicate content is not always visible at first glance.
Regular audits, proper canonical implementation, and Google Search Console checks will help you stay in control.
Think of this process as maintenance for your site’s health — consistent checking ensures your best pages get the visibility they deserve.
How Duplicate Content Affects SEO Efforts and Backlink Equity
Google may not penalize duplicate content, but it can still hurt your SEO performance in serious ways.
It affects how search engines understand your site, how backlinks are distributed, and how efficiently your pages get crawled and indexed.
Let’s look at how each of these factors plays out in real SEO practice.
1. Dilution of Link Equity
Backlinks are one of the strongest ranking signals.
But when multiple pages carry the same content, external sites might link to different versions.
This splits your link equity.
Instead of one strong page getting all the power, you end up with several weak ones.
For example:
If five websites link to five duplicate versions of a product page, each version only gets a small portion of authority.
If all those backlinks pointed to one canonical page, your ranking power would multiply.
That’s why consolidating links using canonical tags or 301 redirects is essential for preserving link value.
2. Ranking Confusion
When Google finds multiple similar pages, it must decide which one to show in search results.
It often picks the version it believes is most relevant, even if it’s not the one you want.
This can result in:
- The wrong URL ranking instead of your optimized page
- Fluctuating rankings between duplicate versions
- Loss of control over what users see in search
Google’s filtering system doesn’t notify you when it hides duplicates — you only notice when your key pages start losing visibility.
3. Wasted Crawl Budget
Search engines allocate a limited crawl budget to each website.
Duplicate pages waste that budget.
Instead of crawling your new, valuable pages, crawlers spend time reloading identical content.
This slows down indexing and can delay updates to your important pages.
A 2024 WebApex study found that sites with over 25% duplicate URLs saw a 40% delay in new page indexing compared to clean sites.
For large websites, especially e-commerce or news sites, this can impact traffic significantly.
4. Impact on Internal Linking and Anchor Distribution
Internal links are critical for SEO, but duplicate URLs often break that structure.
When internal links point to multiple versions of the same page, authority spreads unevenly.
As a result, Google may undervalue your main page, even if it’s the most optimized.
That’s why all internal links should consistently point to the canonical version.
5. Syndicated or Reposted Content Issues
Publishing your content on other platforms (like Medium or partner websites) can be a smart visibility tactic — but only if done correctly.
If syndication lacks a canonical tag or clear attribution, the external version might outrank yours.
This often happens when big platforms republish smaller sites’ content.
Always ensure syndicated content includes a canonical link back to your original article.
If that’s not possible, ask for a rel=”nofollow” link or unique summary instead of the full post.
6. Backlink Risks with Duplicates
Backlinks that point to duplicate pages can weaken your off-page SEO.
Even if total backlinks remain high, the “ranking weight” doesn’t concentrate on the right URL.
Example:
A website with 100 backlinks spread across five duplicate pages might pass the same power as only 20 strong backlinks to one page.
Consolidation is key for authority growth.
7. Analytics and Performance Tracking Confusion
Duplicate URLs can also confuse tracking data.
Traffic splits between versions, making it hard to measure performance accurately.
This leads to wrong decisions in SEO planning.
By consolidating content and using canonical tags, you ensure accurate data for keyword tracking, user behavior, and conversions.
In Short
Duplicate content may not get you penalized, but it can still damage your SEO efficiency.
It divides backlinks, wastes crawl budget, and creates ranking confusion.
Fixing these issues through canonicalization, redirects, and proper syndication helps Google focus all your SEO power on the right pages — where it truly counts.
Duplicate Content in the AI Era – What Changes and What to Focus On
AI is changing how search engines and users find information.
Duplicate content issues are not new, but their impact is evolving fast in the age of AI-driven search.
In the past, duplicate content mainly affected rankings.
Now, it can affect your visibility in AI-generated results, brand credibility, and even how your site is used as a data source for machine learning systems.
1. AI Tools Depend on Original and Authoritative Content
AI-powered search tools like Google’s SGE (Search Generative Experience), ChatGPT Search, and Perplexity summarize information from multiple trusted sources.
If your site content matches many others online, AI may skip it.
These systems are trained to prefer content that is unique, detailed, and trustworthy.
Duplicate or lightly rewritten pages have a lower chance of being cited, summarized, or ranked in AI-driven answers.
In simple words, AI wants the best version of every idea, not more copies.
2. Canonical Tags Are Becoming More Important
In AI SEO, canonical tags help systems identify the original source of information.
If your content is syndicated or quoted elsewhere, a canonical tag signals ownership.
This helps search engines and AI tools understand which version to prioritize when displaying or summarizing information.
Without clear canonical signals, your content might strengthen another website’s authority instead of yours.
3. Entity Understanding and Contextual Authority
AI doesn’t just look at words — it understands entities, context, and relationships between topics.
If your website repeatedly uses duplicate or thin content, AI may consider it less authoritative for that entity or topic cluster.
For example:
If five blogs repeat the same article about “Local SEO Tips,” but one has structured data, internal links, and expert author signals, AI will prefer that one.
Original context and value now matter more than ever.
4. Duplicate Content Affects E-E-A-T Signals
Google’s and AI’s ranking systems rely heavily on Experience, Expertise, Authority, and Trust (E-E-A-T).
Duplicate content weakens all four.
- It reduces perceived expertise because your content doesn’t stand out.
- It lowers authority since others might appear as the original source.
- It affects trust, as AI tools prioritize verified and distinct voices.
Maintaining uniqueness, adding expert commentary, and citing credible sources help preserve strong E-E-A-T signals.
5. AI Detection Systems Can Flag Low-Value Duplicates
Search engines and AI crawlers can now detect duplication more intelligently.
They analyze structure, metadata, authorship, and publication time.
Even small rewrites of the same idea can be recognized as duplicates.
That means creating unique perspectives, fresh data, or regional insights is the new SEO advantage.
In the AI era, creativity and originality drive higher visibility.
6. Best Practices for the AI Era
To handle duplicate content effectively in AI SEO, follow these rules:
- Always use canonical tags to mark original sources.
- Avoid mass-rewriting old content without adding new insights.
- Focus on entity-driven SEO with topic depth and internal linking.
- Add author details, reviews, and data to prove credibility.
- If syndicating content, ensure the external site uses canonical or “nofollow” links.
- Use structured data (
Article,Author,Organization) for clarity.
These signals help AI understand your content’s origin, context, and authority.
7. The Future View
As AI systems become more powerful, the web will reward clarity, originality, and context.
Duplicate or low-value content will fade from search visibility.
The good news is, if you handle canonicalization properly and focus on quality, AI will recognize your brand as a trusted data source.
That trust will amplify your SEO efforts, backlinks, and future rankings.
In Short
In the AI era, duplicate content doesn’t just waste ranking potential — it weakens your visibility across all intelligent platforms.
Focus on originality, entity authority, and clear canonical signals to make your content AI-friendly and future-proof.
Practical Checklist / Roadmap for Handling Duplicate Content
Duplicate content is easy to control when you follow a clear process.
This roadmap will help you detect, fix, and prevent duplication issues — while keeping your SEO and AI visibility strong.
Step 1: Run a Full Duplicate Content Audit
Start with a complete site crawl using tools such as:
- Screaming Frog
- Ahrefs Site Audit
- SEMrush
- SiteGuru or Siteliner
Look for:
- Identical or near-identical body content
- Duplicate titles or meta descriptions
- Multiple URLs displaying the same page
- Printer versions or tag archives in CMSs like WordPress
Export the duplicate list and organize it by priority (important pages first).
Step 2: Choose the Preferred (Canonical) Version
For every duplicate group, select one canonical version — the page you want to keep indexed.
Consider:
- Which page has more backlinks
- Which URL is clean, short, and user-friendly
- Which version gets better engagement
All other versions should point to this one as the preferred page.
Step 3: Apply the Correct Technical Fix
Use the right fix depending on the situation:
| Problem Type | Recommended Fix |
|---|---|
| Identical internal pages | Add a canonical tag to the preferred URL |
| Outdated or duplicate version | Apply a 301 redirect to the main page |
| Faceted navigation or filter parameters | Use self-referencing canonicals + consistent internal links |
| Session or tracking parameters | Use canonical tags on clean URLs and block parameters with robots.txt if safe |
| Syndicated or partner content | Ask for a canonical tag to your page or a rel=”nofollow” link |
Note: Google no longer provides the URL Parameters tool in Search Console.
Instead, use canonicals, structured data, and internal linking to guide Google automatically.
Step 4: Consolidate Backlinks
Check which duplicate URLs have backlinks using tools like Ahrefs or Majestic.
If possible, contact webmasters to update links to the canonical URL.
If not, add 301 redirects so all link equity flows to the preferred version.
This ensures that every backlink strengthens your main page, not the duplicates.
Step 5: Fix Internal Linking
Make sure every internal link on your site points to the canonical version.
Avoid linking to redirected or parameter-based URLs.
Consistent linking improves crawl efficiency and authority flow.
Step 6: Monitor Canonicalization and Indexing
After applying fixes, track how Google handles your updates.
Use:
- Google Search Console → Inspect URL to check the user-declared and Google-selected canonical.
- Ahrefs or SEMrush to monitor traffic and backlink movement.
- Index Coverage Report to ensure old versions are dropping and canonicals are rising.
It usually takes a few weeks for Google to reflect the changes fully.
Step 7: Prevent Duplicate Content in the Future
Prevention saves time and ranking power. Follow these habits:
- Use lowercase, clean, and consistent URLs.
- Avoid thin or repetitive blog posts on similar topics.
- Write unique titles, meta tags, and headers for every page.
- Use canonical tags in your CMS templates by default.
- Ensure your site uses only one version (HTTPS + either www or non-www).
Step 8: Stay AI-Ready
In the AI-driven world, clear canonical signals and originality matter more than ever.
Follow these AI-friendly practices:
- Keep canonical and structured data accurate.
- Add authorship schema and brand schema.
- Publish original insights and statistics instead of reusing common content.
- If content is syndicated, make sure your site is cited as the original source.
AI systems like Gemini and Perplexity rely on signals like authority, originality, and clarity to determine which source to feature.
Step 9: Review Quarterly
SEO changes over time.
Do a duplicate content audit every quarter.
Check your canonicals, redirects, and backlinks to ensure they remain consistent.
Regular maintenance keeps your crawl budget clean, rankings stable, and authority strong.
In Short
Duplicate content doesn’t bring penalties — but it can waste your SEO potential.
With the right structure, canonicalization, and consistent linking, you can ensure Google and AI systems always recognize your content as the original source.
Conclusion
Duplicate content is not a penalty issue. It is a clarity issue.
Google does not punish websites for having similar pages, but it must choose which version to show.
If you don’t guide it clearly, you risk losing visibility, backlinks, and control over your search results.
Canonical tags, redirects, and consistent internal linking solve most duplicate content problems.
These tools help search engines understand your structure and combine all ranking signals in the right place.
In the AI era, this becomes even more important.
AI-driven systems like Google SGE, Gemini, and ChatGPT Search look for unique, authoritative, and clearly attributed content.
If your site sends mixed signals or reuses existing material, it may disappear from AI-generated results — even if it ranks in traditional search.
That’s why duplicate management is no longer a small technical task.
It’s part of building strong authority and trust for your brand.
A clean, canonical, and original website sends a single message to both Google and AI:
“This is the real source.”
When you own that position, your backlinks consolidate, your rankings stay stable, and your brand earns long-term visibility across every search and AI platform.
Frequently Asked Questions (FAQ)
1. Does Google penalize duplicate content?
No. Google has confirmed there is no penalty for duplicate content unless it’s used to manipulate rankings or deceive users.
However, Google may filter out similar pages and show only one version in search results.
So, while there’s no punishment, duplicates can still reduce your visibility and traffic.
2. What is a canonical tag in SEO?
A canonical tag is an HTML signal that tells Google which version of a page is the preferred one.
Example:
<link rel="canonical" href="https://example.com/preferred-page/" />
This helps consolidate link equity and prevent duplicate content problems.
3. How do I find duplicate content on my website?
You can detect duplicates using tools like Screaming Frog, Ahrefs Site Audit, SEMrush, or SiteGuru.
Also check Google Search Console for “Duplicate URL” messages under the Pages report.
Manual checks with the site: operator and content snippets in quotes also work well.
4. What should I do if other websites copy my content?
If your content appears on other domains, ask them to:
- Add a canonical tag pointing to your page, or
- Include a rel=”nofollow” link for attribution.
If they refuse, you can submit a DMCA request to Google to remove the copied version from search results.
5. Can I republish my own articles on other platforms?
Yes, but do it carefully.
When syndicating content to sites like Medium or LinkedIn, always:
- Add a canonical link back to your original post, or
- Use a rewritten, shorter version with a link to the full post.
This protects your rankings and ensures you remain the original source in Google’s eyes.
6. How does duplicate content affect backlinks?
Duplicate URLs can split backlinks across multiple pages, reducing the authority of your main content.
Using 301 redirects or canonical tags helps combine link equity so your preferred page gains full ranking strength.
7. Does duplicate content affect AI-driven SEO?
Yes. AI-based systems like Gemini and ChatGPT Search prioritize unique and authoritative content.
Duplicate or republished content is less likely to be cited or summarized.
Clear canonical tags, structured data, and strong E-E-A-T signals help AI identify your site as the original source.
8. How do I prevent duplicate content on a WordPress site?
- Use canonical tags in your theme header.
- Avoid publishing similar posts with minor wording changes.
- Disable tag and category archives if they generate duplicates.
- Ensure one preferred domain version (HTTPS and either www or non-www).
- Use a plugin like Yoast SEO or Rank Math to automate canonical handling.
9. How often should I check for duplicate content?
Run a full SEO audit every three to six months.
Also, recheck after major site updates, content migrations, or redesigns.
Regular reviews help maintain clean indexation and strong ranking signals.
10. Does duplicate content still matter in 2025?
Absolutely.
While Google handles duplicates better now, your SEO and AI visibility still depend on clarity.
In the 2025 AI-driven search environment, only unique, clearly attributed content builds authority and gets surfaced in AI answers.
Final Takeaway
Duplicate content is not a penalty trap — it’s a clarity test.
When you guide Google and AI correctly using canonical tags, redirects, and unique insights, your brand earns trust, backlinks, and long-term visibility that no short-term fix can match.
